
Signal released end-to-end encrypted group calls a year ago, and since then we’ve scaled from support for 5 participants all the way to 40. There is no off the shelf software that would allow us to support calls of that size while ensuring that all communication is end-to-end encrypted, so we built our own open source Signal Calling Service to do the job. This post will describe how it works in more detail.
Selective Forwarding Units (SFUs)
In a group call, each party needs to get their audio and video to every other participant in the call. There are 3 possible general architectures for doing so:
- Full mesh: Each call participant sends its media (audio and video) directly to each other call participant. This works for very small calls, but does not scale to many participants. Most people just don’t have an Internet connection fast enough to send 40 copies of their video at the same time.
- Server mixing: Each call participant sends its media to a server. The server “mixes” the media together and sends it to each participant. This works with many participants, but is not compatible with end-to-end encryption because it requires that the server be able to view and alter the media.
- Selective Forwarding: Each participant sends its media to a server. The server “forwards” the media to other participants without viewing or altering it. This works with many participants, and is compatible with end-to-end-encryption.
Because Signal must have end-to-end encryption and scale to many participants, we use selective forwarding. A server that does selective forwarding is usually called a Selective Forwarding Unit or SFU.
If we focus on the flow of media from a single sending participant through an SFU to multiple receiving participants, it looks like this:
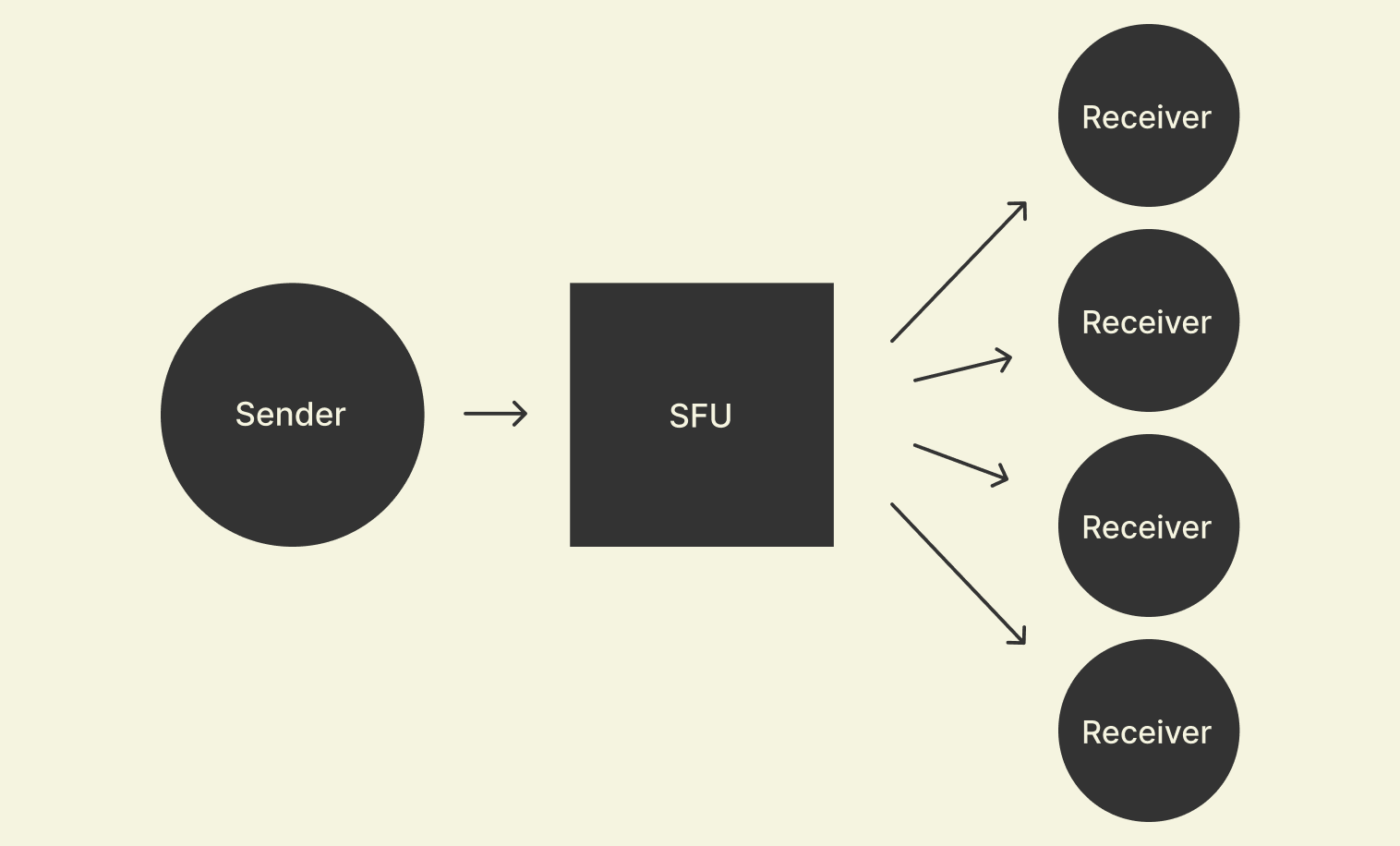
A simplified version of the main loop in the code in an SFU looks like this:
let socket = std::net::UdpSocket::bind(config.server_addr);
let mut clients = ...; // changes over time as clients join and leave
loop {
let mut incoming_buffer = [0u8; 1500];
let (incoming_size, sender_addr) = socket.recv_from(&mut incoming_buffer);
let incoming_packet = &incoming_buffer[..incoming_size];
for receiver in &clients {
// Don't send to yourself
if sender_addr != receiver.addr {
// Rewriting the packet is needed for reasons we'll describe later.
let outgoing_packet = rewrite_packet(incoming_packet, receiver);
socket.send_to(&outgoing_packet, receiver.addr);
}
}
}
Signal’s Open Source SFU
When building support for group calls, we evaluated many open source SFUs, but only two had adequate congestion control (which, as we’ll see shortly, is critical). We launched group calls using a modified version of one of them, but shortly found that even with heavy modifications, we couldn’t reliably scale past 8 participants due to high server CPU usage. To scale to more participants, we wrote a new SFU from scratch in Rust. It has now been serving all Signal group calls for 9 months, scales to 40 participants with ease (perhaps more in the future), and is readable enough to serve as a reference implementation for an SFU based on the WebRTC protocols (ICE, SRTP, transport-cc, and googcc).
Let’s now take a deeper dive into the hardest part of an SFU. As you might have guessed, it’s more complex than the simplified loop above.
The Hardest Part of an SFU
The hardest part of an SFU is forwarding the right video resolutions to each call participant while network conditions are constantly changing.
This difficulty is a combination of the following fundamental problems:
- The capacity of each participant’s Internet connection is constantly changing and hard to know. If the SFU sends too much, it will cause additional latency. If the SFU sends too little, the quality will be low. So the SFU must constantly and carefully adjust how much it sends each participant to be “just right”.
- The SFU cannot modify the media it forwards; to adjust how much it sends, it must select from media sent to it. If the “menu” to select from were limited to sending either the highest resolution available or nothing at all, it would be difficult to adjust to a wide variety of network conditions. So each participant must send the SFU multiple resolutions of video and the SFU must constantly and carefully switch between them.
The solution is to combine several techniques which we will discuss individually:
- Simulcast and Packet Rewriting allow switching between different video resolutions.
- Congestion Control determines the right amount to send.
- Rate Allocation determines what to send within that budget.
Simulcast and Packet Rewriting
In order for the SFU to be able to switch between different resolutions, each participant must send to the SFU many layers (resolutions) simultaneously. This is called simulcast. If we focus on just one sender’s media being forwarded to two receivers, it looks like this, where each receiver switches between small and medium layers but at different times:

But what does the receiving participant see as the SFU switches between different layers? Does it see one layer switching resolutions or does it see multiple layers switching on and off? This may seem like a minor distinction, but it has major implications for the role the SFU must play. Some video codecs, such as VP9 or AV1, make this easy: switching layers is built into the video codec in a way called SVC. Because we’re still using VP8 to support a wide range of devices, and since VP8 doesn’t support SVC, the SFU must do something to transform 3 layers into 1.
This is similar to how video streaming apps stream different quality video to you depending on how fast your Internet connection is. You view a single video stream switching between different resolutions, and in the background, you are receiving different encodings of the same video stored on the server. Like a video streaming server, the SFU sends you different resolutions of the same video. But unlike a video streaming server, there is nothing stored and it must do this completely on the fly. It does so via a process called packet rewriting.
Packet rewriting is the process of altering the timestamps, sequence numbers, and similar IDs that are contained in a media packet that indicate where on a media timeline a packet belongs. It transforms packets from many independent media timelines (one for each layer) into one unified media timeline (one layer). The IDs that must be rewritten when using RTP and VP8 are the following:
- RTP SSRC: Identifies a stream of consecutive RTP packets. Each simulcast layer is identified by a unique SSRC. To convert from many layers (for example, 1, 2, and 3) to one layer, we must change (rewrite) this value to the same value (say, 1).
- RTP sequence number: Orders the RTP packets that share an SSRC. Because each layer has a different number of packets, it is not possible to forward packets from multiple layers without changing (rewriting) the sequence numbers. For example, if we want to forward sequence numbers [7, 8, 9] from one layer followed by [8, 9, 10, 11] from another layer, we can’t send them as [7, 8, 9, 9, 10, 11]. Instead we’d have to rewrite them as something like [7, 8, 9, 10, 11, 12, 13].
- RTP timestamp: Indicates when a video should be rendered relative to a base time. Because the WebRTC library we use chooses a different base time for each layer, the timestamps are not compatible between layers, and we must change (rewrite) the timestamps of one layer to match that of another.
- VP8 Picture ID and TL0PICIDX: Identifies a group of packets which make up a video frame, and the dependencies between video frames. The receiving participant needs this information to decode the video frame before rendering. Similar to RTP timestamps, the WebRTC library we use chooses different sets of PictureIDs for each layer, and we must rewrite them when combining layers.
It would be theoretically possible to only rewrite just the RTP SSRCs and sequence numbers if we altered the WebRTC library to use consistent timestamps and VP8 PictureIDs across layers. However, we already have many clients in use generating inconsistent IDs, so we need to rewrite all of those IDs to remain backwards compatible. And since the code to rewrite the various IDs is almost identical to rewriting RTP sequence numbers, it’s not difficult to do so.
To transform a single outgoing layer from multiple incoming layers for a given video stream, the SFU rewrites packets according to the following rules:
- The outgoing SSRC is always the incoming SSRC of the smallest layer.
- If the incoming packet has an SSRC other than the one currently selected, don’t forward it.
- If the incoming packet is the first after a switch between layers, alter the IDs to represent the latest position on the outgoing timeline (one position after the maximum position forwarded so far).
- If the incoming packet is a continuation of packets after a switch (it hasn’t just switched), alter the IDs to represent the same relative position on the timeline based on when the switch occurred in the previous rule.
For example, if we had two input layers with SSRCs A and B and a switch occured after two packets, packet rewriting may look something like this:
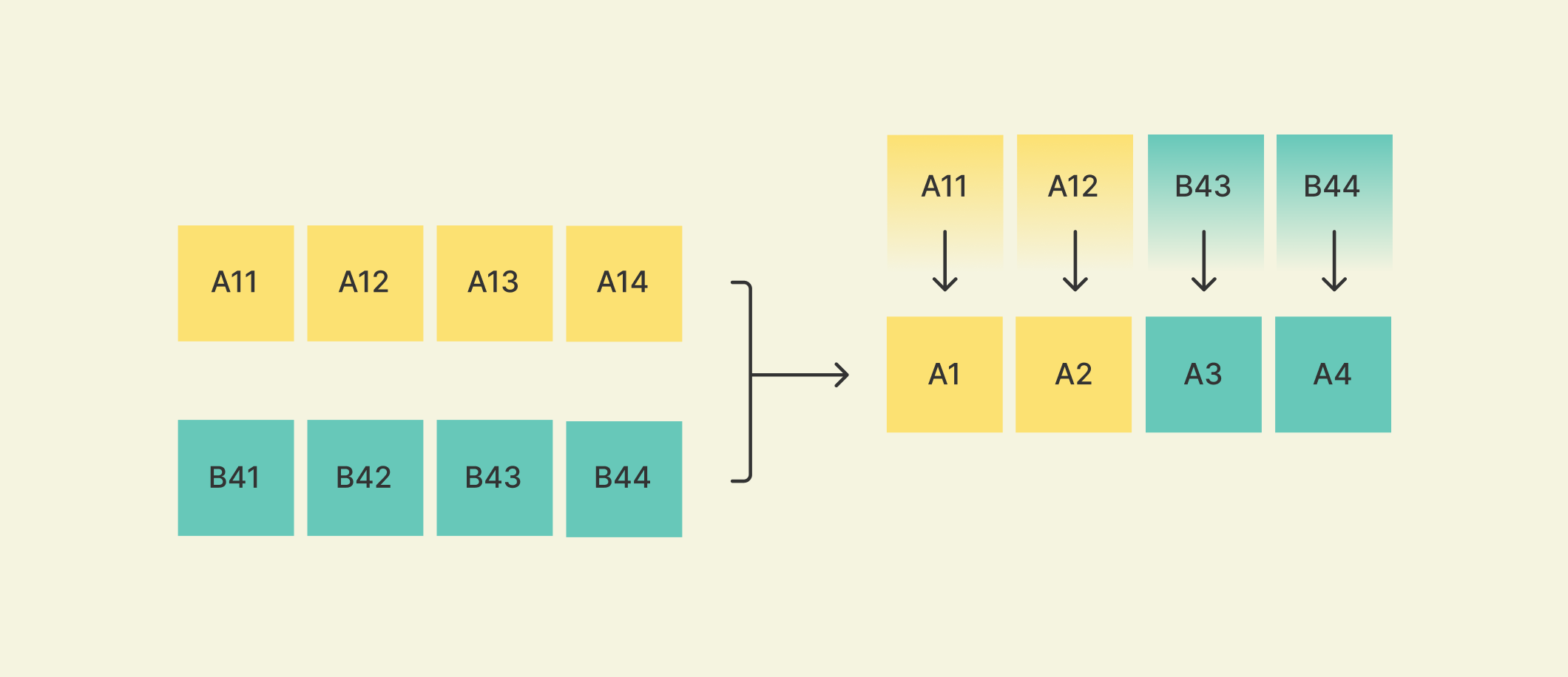
A simplified version of the code looks something like this:
let mut selected_ssrc = ...; // Changes over time as bitrate allocation happens
let mut previously_forwarded_incoming_ssrc = None;
// (RTP seqnum, RTP timestamp, VP8 Picture ID, VP8 TL0PICIDX)
let mut max_outgoing_ids = (0, 0, 0, 0);
let mut first_incoming_ids = (0, 0, 0, 0);
let mut first_outgoing_ids = (0, 0, 0, 0);
for incoming in incoming_packets {
if selected_ssrc == incoming.ssrc {
let just_switched = Some(incoming.ssrc) != previously_forwarded_incoming_ssrc;
let outgoing_ids = if just_switched {
// There is a gap of 1 seqnum to signify to the decoder that the
// previous frame was (probably) incomplete.
// That's why there's a 2 for the seqnum.
let outgoing_ids = max_outgoing + (2, 1, 1, 1);
first_incoming_ids = incoming.ids;
first_outgoing_ids = outgoing_ids;
outgoing_ids
} else {
first_outgoing_ids + (incoming.ids - first_incoming_ids)
}
yield outgoing_ids;
previous_outgoing_ssrc = Some(incoming.ssrc);
max_outgoing_ids = std::cmp::max(max_outgoing_ids, outgoing_ids);
}
}
Packet rewriting is compatible with end-to-end encryption because the rewritten IDs and timestamps are added to the packet by the sending participant after the end-to-end encryption is applied to the media (more on that below). It is similar to how TCP sequence numbers and timestamps are added to packets after encryption when using TLS. This means the SFU can view these timestamps and IDs, but these values are no more interesting than TCP sequence numbers and timestamps. In other words, the SFU doesn’t learn anything from these values except that the participant is still sending media.
Congestion Control
Congestion control is a mechanism to determine how much to send over a network: not too much and not too little. It has a long history, mostly in the form of TCP’s congestion control. Unfortunately, TCP’s congestion control algorithms generally don’t work well for video calls because they tend to cause increases in latency that lead to a poor call experience (sometimes called “lag”). To provide good congestion control for video calls, the WebRTC team created googcc, a congestion control algorithm which can determine the right amount to send without causing large increases in latency.
Congestion control mechanisms generally depend on some kind of feedback mechanism sent from the packet receiver to the packet sender. googcc is designed to work with transport-cc, a protocol in which the receiver sends periodic messages back to the sender saying, for example, “I received packet X1 at time Z1; packet X2 at time Z2, …”. The sender then combines this information with its own timestamps to know, for example, “I sent packet X1 at time Y1 and it was received at Z1; I sent packet X2 at time Y2 and it was received at Z2…”.
In the Signal Calling Service, we have implemented googcc and transport-cc in the form of stream processing. The inputs into the stream pipeline are the aforementioned data about when packets were sent and received, which we call acks. The outputs of the pipeline are changes in how much should be sent over the network, which we call the target send rates.
The first few steps of the flow plot the acks on a graph of delay vs. time and then calculate a slope to determine if the delay is increasing, decreasing, or steady. The last step decides what to do based on the current slope. A simplified version of the code looks like this:
let mut target_send_rate = config.initial_target_send_rate;
for direction in delay_directions {
match direction {
DelayDirection::Decreasing => {
// While the delay is decreasing, hold the target rate to let the queues drain.
}
DelayDirection::Steady => {
// While delay is steady, increase the target rate.
let increase = ...;
target_send_rate += increase;
yield target_send_rate;
}
DelayDirection::Increasing => {
// If the delay is increasing, decrease the rate.
let decrease = ...;
target_send_rate -= decrease;
yield target_send_rate;
}
}
}
This is the crux of googcc: If latency is increasing, stop sending so much. If latency is decreasing, let it continue. If latency is steady, try sending more. The result is a send rate which closely approximates the actual network capacity while adjusting to changes and keeping latency low.
Of course, the “…” in the code above about how much to increase or decrease is complicated. Congestion control is hard. But now you can see how it generally works for video calls:
- The sender picks an initial rate and starts sending packets.
- The receiver sends back feedback about when it received the packets.
- The sender uses that feedback to adjust the send rate with the rules described above.
Rate Allocation
Once the SFU knows how much to send, it now must determine what to send (which layers to forward). This process, which we call rate allocation, is like the SFU choosing from a menu of layers constrained by a send rate budget. For example, if each participant is sending 2 layers and there are 3 other participants, there would be 6 total layers on the menu.
If the budget is big enough, we can send everything we want (up to the largest layer for each participant). But if not, we must prioritize. To aid in prioritization, each participant tells the server what resolutions it needs by requesting a maximum resolution. Using that information, we use the following rules for rate allocation:
- Layers larger than the requested maximum are excluded. For example, there is no need to send you high resolutions of every video if you’re only viewing a grid of small videos.
- Smaller layers are prioritized over larger layers. For example, it is better to view everyone in low resolution rather than some in high resolution and others not at all.
- Larger requested resolutions are prioritized before smaller requested resolutions. For example, once you can see everyone, then the video that appears largest to you will fill in with higher quality before the others.
A simplified version of the code looks like the following.
// The input: a menu of video options.
// Each has a set of layers to choose from and a requested maximum resolution.
let videos = ...;
// The output: for each video above, which layer to forward, if any
let mut allocated_by_id = HashMap::new();
let mut allocated_rate = 0;
// Biggest first
videos.sort_by_key(|video| Reverse(video.requested_height));
// Lowest layers for each before the higher layer for any
for layer_index in 0..=2 {
for video in &videos {
if video.requested_height > 0 {
// The first layer which is "big enough", or the biggest layer if none are.
let requested_layer_index = video.layers.iter().position(
|layer| layer.height >= video.requested_height).unwrap_or(video.layers.size()-1)
if layer_index <= requested_layer_index {
let layer = &video.layers[layer_index];
let (_, allocated_layer_rate) = allocated_by_id.get(&video.id).unwrap_or_default();
let increased_rate = allocated_rate + layer.rate - allocated_layer_rate;
if increased_rate < target_send_rate {
allocated_by_id.insert(video.id, (layer_index, layer.rate));
allocated_rate = increased_rate;
}
}
}
}
}
Putting it all together
By combining these three techniques, we have a full solution:
- The SFU uses googcc and transport-cc to determine how much it should send to each participant.
- The SFU uses that budget to select video resolutions (layers) to forward.
- The SFU rewrites packets from many layers into one layer for each video stream.
The result is that each participant can view all the others in the best way possible given the current network conditions, and in a way compatible with end-to-end-encryption.
End-to-end encryption
Speaking of end-to-end encryption, it’s worth briefly describing how it works. Because it’s completely opaque to the server, the code for it is not in the server, but rather in the client. In particular, our implementation exists in RingRTC, an open source video calling library written in Rust.
The contents of each frame are encrypted before being divided into packets, similar to SFrame. The interesting part is really the key distribution and rotation mechanism, which must be robust against the following scenarios:
- Someone who has not joined the call must not be able to decrypt media from before they joined. If this were not the case, someone who could obtain the encrypted media (such as by compromising the SFU) would be able to know what happened in the call before they joined, or worse, without ever having joined.
- Someone who has left the call must not be able to decrypt media from after they left. If this were not the case, someone who could obtain the encrypted media would be able to know what happened in the call after they left.
In order to guarantee these properties, we use the following rules:
- When a client joins the call, it generates a key and sends it to all other clients of the call over Signal messages (which are themselves end-to-end encrypted) and uses that key to encrypt media before sending it to the SFU.
- Whenever any user joins or leaves the call, each client in the call generates a new key and sends it to all clients in the call. It then begins using that key 3 seconds later (allowing for some time for clients to receive the new key).
Using these rules, each client is in control of its own key distribution and rotation and rotates keys depending on who is in the call, not who is invited to the call. This means that each client can verify that the above security properties are guaranteed.
We hope people enjoy support for large group end-to-end video calls, and that our open source Secure Calling Service is useful for anyone that wants to build and deploy their own end-to-end encrypted group video calls. And we’re hiring if you’re interested in working on problems like these at Signal!